Sequence Rendering
Non-linear video sequencers have traditionally had a processing model that relied on a frame-by-frame rendering of the output. That is, for each frame of output, the sequencer would render each relevant input at that frame, composite the inputs, and output a single output frame. This model is simple, but has several disadvantages, all rooted in the fact that inter-frame information is thrown away or not accessible to the processor. A processing model is described where the iteration is inverted - we render each input sequence first, and the composite the rendered sequences to produce an output sequence.
This is part of a project of mine to get features such as image stabilization into Blender, the open source 3d package. I started a thread on the bf-committers list titled VSE Strip-Wise Rendering[a], if anyone is interested in the history of the project.
1. Background
A video sequence editor is a tool that enables a user to process and mix video clips. The editor is used to assemble a number of input clips into a single output movie. Typically, the input clips are represented as strips lying along a time line:
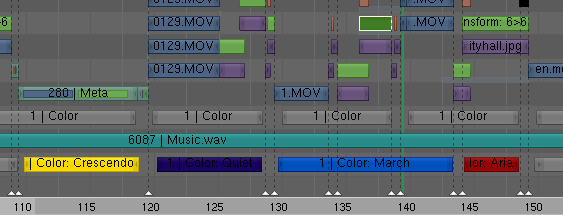
The video sequence editor further has a number of "channels", or the ability to stack the strips on top of each other. If two strips overlap, the editor will use one or both to produce the output. For example, fading between two clips would be done by stacking them on top of each other and telling the editor to composite them using a fade operation.
The internal processing when rendering the output movie is typically done in the fashion illustrated below:

That is, the editor starts at the first frame, and then renders and composites the input strips in one pass, producing one output frame. The current frame is then advanced, and the editor makes another pass over the input strips. This continues until the last frame has been rendered.
The advantages with this processing model are many: It is very easy to understand. It is very easy to distribute on a rendering farm. It requires very little resources, as you need to hold at most one frame from each strip in the working set at any given moment. Due to the simplicity of the algorithm, it is also easy to implement and code for. If we, for example, want to write a filter that inverts the colors of each frame, we can implement it as a function taking an input image and returning an output image. Since this enables us to ignore the sequencing and just focus on processing a single image, the complexity of the code is similarly reduced.
1.1. Disadvantages
The disadvantages come when we wish to perform any kind of processing that requires access to more than just the current frame. The frames in the sequencer aren't just random jumbles of image data, but sequences of images that have a lot of inter-frame information: Object motion, for example, is something that is impossible to compute given a single frame, but possible with two or more frames.
Another use case that is very difficult with frame-wise rendering is adjusting the frame rate of a clip. When mixing video from different sources one can't always assume that they were filmed at the same frame rate. If we wish to re-sample a video clip along the time axis, we need access to more than one frame in order to handle the output frames that fall in-between input frames - which usually is most of them.
2. Sequence Rendering
In the sequence rendering model we swap the order of rendering. When we previously did:
|
We will now switch the nesting of the for loops, and move the compositing stage to the very end. A naive implementation would be:
|


This enables us to work with sequences as opposed to individual, isolated frames. Frame rate adjustment and optical flow become easy to implement.
While this model requires a bit more care when coding, we retain all other advantages from the frame-wise rendering process. In particular, we retain the ability to split processing on a number of render nodes.
3. Prototype
In order to explore this rendering model before trying to integrate it with Blender, I implemented a sequence renderer in Java. The reason for choosing Java is that it is a lot easier to test things out in that language than C or C++, and I had a lot of image processing code written in Java already. For those Blender developers reading this - I have no intention of putting Java into Blender. The code below is for illustrative purposes, and I hope you can follow the thoughts behind the code, even if the language looks unfamiliar.
The interfaces can be roughly split into two groups: one for the sequences, and one for the processor. The sequences are the different types of inputs and transformations applied to them, such as movie clips, sound, image stabilization, frame rate adjustment and color correction. The processor deals with the caching of intermediate results and the distribution of work during rendering.
3.1. Sequence Interfaces
When designing the interfaces I chose to implement a sequence as similar to an iterator, as opposed to a random-access interface. The rationale behind this is twofold: The goal was to enable the creation of sequence types that had access to more than one frame of the input. These sequences turned out to be the kind that would lend themselves naturally to being rendered sequentially. For example, any sequence dependent on computing optical flow would be much easier to implement if it knew it would output consecutive frames. The second reason is that a random access interface can be built on top of the iterator interface, but it is much harder to implement a sequential interface on top of a random-access interface and retain efficiency.[1]
3.2. Sequence
This is the interface implemented by all sequence types. A sequence, by itself, has no "position" in the output - that is supposed to be handled by a specialized MixSequence implementation that isn't relevant for the purposes of examining the rendering process concept.
public interface Sequence<T> {
public double framerate ();
public double timestep ();
public int size ();
public RenderMode renderMode ();
public RenderSource<T> render (
int startSample,
int endSample)
throws Exception;
}3.2.1. framerate
The frame rate of the sequence, in frames / second.
3.2.2. timestep
The time in seconds between frames. Equal to 1.0 / framerate().
3.2.3. size
Number of frames in this sequence.
3.2.4. renderMode
The render mode for this sequence, used by the processor to render the sequence in the most efficient way.
3.2.5. render
Provides a render source for the given subsequence.
3.3. RenderMode
The render mode specifies how a sequence should be rendered by the processor. Based on the rendering environment, the sequence processor will use this value, that must be a constant for each sequence, to render the final output in the most efficient way.
public static enum RenderMode {
PASSTHROUGH,
SINGLE,
CHUNKED,
SEQUENTIAL,
FULL;
}3.3.1. PASSTHROUGH
Disable intelligent processing for this sequence. This is used for sequence types that do not perform any processing of the image data - for example, output sequences and sequences whose purpose is to write log entries during certain events.
3.3.2. SINGLE
This sequence consists of independent frames and can be rendered one frame at a time without any loss of efficiency.
3.3.3. CHUNKED
This sequence consists of frames that have dependencies on each other. It can be rendered as individual frames, but the bigger chunks that can be rendered at a time, the better. This is typically for sequences that have a high startup cost that can be amortized over all frames. One example of this is computing optical flow - in order to compute the optical flow for a single frame, you need two input frames. But in order to compute the flow for two frames, you need three input frames, not four. In general, you need N + 1 input frames for N output frames. As N grows larger, the cost of the extra input frame becomes smaller and smaller relative to the total cost.
3.3.4. SEQUENTIAL
Like a CHUNKED sequence, but the sequence has such huge fixed cost that it should be rendered all in one go, on a single node.
3.3.5. FULL
Like SEQUENTIAL, but the sequence also has the property that in order to render frame n, all the previous n - 1 frames must be rendered.
3.4. RenderSource
A render source is an iterator over a sequence and is the interface through which clients of a sequence gets the data in it. The frame numbers the source refers to are local to the sequence it iterates over, and not any global frame number.
public interface RenderSource<T> {
public T next () throws Exception;
public boolean hasNext ();
public int nextFrame ();
public int firstFrame ();
public int lastFrame ();
public void close ()
throws Exception;
}3.4.1. next
Produces and returns the next element in the sequence.
3.4.2. hasNext
True if we are not at the end of this sequence.
3.4.3. nextFrame
The index of the next frame that next will return.
3.4.4. firstFrame
The index of the first frame that this source will return or has returned.
3.4.5. lastFrame
The index of the last-plus-one frame that this source will return.
3.4.6. close
Closes this render source and frees associated resources.
3.5. Processor Interfaces
The processor interfaces are used by clients to set up sequences and render the final output. Sequences are added to the processor, which returns a unique sequence handle for each sequence that is added. The processor may also wrap the sequence in a caching wrapper. One should therefore only access sequences using the get method.
3.6. SequenceProcessor
public interface SequenceProcessor {
public <T> SequenceHandle<T> add (
Sequence<T> seq);
public <T> Sequence<T> get (
SequenceHandle<T> id);
public void render (
SequenceHandle<?> id,
int start,
int end)
throws Exception;
public void render (
SequenceHandle<?> id)
throws Exception;
}3.6.1. add
Adds a sequence to the processor. The processor will typically proxy the sequence instance, so the get method will typically not return the same object as was given to the add method: h = add (seq); seq != get (h);
3.6.2. get
Returns a Sequence interface to the sequence specified by the handle. As the processor may distribute the rendering of the sequence, the instance it returns may vary, and may refer to a proxy for the sequence that was added.
3.6.3. render
Renders the given sequence. The method with three parameters will render a subsequence.
3.7. SequenceHandle
Opaque handle used to refer to sequences in a processor instance.
public interface SequenceHandle<T> {
}3.8. Usage
Example code to apply image stabilization to a video clip:
// Somehow obtain a processor
SequenceProcessor processor = ...;
// Set up input
SequenceHandle<RGBImage> in = processor.add (
new FFMpegInputSequence (inputFile)
);
// Set up the fixed points to use for stabilization
SmoothPanSequence spas = new SmoothPanSequence (false);
spas.setInput (processor.get (in));
spas.add (
new SmoothPanSequence.StaticXYFixPoint (727, 319, 12, 32)
.setActive (30,500));
spas.add (
new SmoothPanSequence.StaticXYFixPoint (363, 214, 12, 32)
.setActive (30,500));
SequenceHandle<RGBImage> hSpas = processor.add (spas);
// Set up output
SequenceHandle<RGBImage> out = processor.add (
new FFMpegOutputSequence (outputFile)
.setInput (processor.get (hSpas))
);
// The processing order is in -> spas (stabilization) -> out
// Render it all
processor.render (out);3.9. Caching
The current implementation of the processor wraps every sequence in a caching wrapper. The wrapper then renders the required frames to an on-disk cache before reading them back. The upside is that every intermediate result is only rendered exactly once, but the downside is that there is a lot of disk usage. Future versions will attempt to hold as much as possible in memory and split the rendering into smaller chunks. See Caching and Disk Use[b] for more about the deficiencies of the current version.
3.10. Issues
The following are some of the issues came to light during development:
3.10.1. Caching and Disk Use
The current, naive, implementation renders every sequence fully before compositing them with no concern for the specified render mode. In the example above, that means first rendering 500 frames of the input sequence to the cache, then reading back each frame, applying the stabilization algorithm to it and writing the results back into the cache. Finally the output sequence iterated over the stabilization results and assembled them into a movie clip. The total amount of on-disk rendering cache was almost 9 GB, and the processing speed was abysmal. The solution would be to implement handling of the render modes in order to minimize disk use.
3.10.2. RenderMode.FULL and RenderMode.SEQUENTIAL Sequences
Any sequence with render mode FULL must be rendered from the very beginning, no matter where in the sequence we want to start reading. SEQUENTIAL is only slightly better. These sequences can't be distributed, and caching is an absolute must for interactive use. It remains open if they should be allowed, or if they will be required to work as CHUNKED sequences, perhaps by letting them temporarily shelve their internal state. The nightmare scenario is for a FULL sequence consisting of 100 frames being called to render first frame 1, then frame 2, and so on. Since it must be rendered from the start, it will be forced to produce first frame 1 then frames 1 and 2, then frames 1, 2, and 3, and so on. This is unlikely in a batch rendering scenario, but very likely in an interactive scenario - for example, when the user scrubs back and forth in the time line. A system that only rendered such sequences on request, and then fully, could eliminate the problem but adds one more thing for the user to remember.
3.10.3. Work Unit Distribution
In the case of CHUNKED sequences, it is not clear how the workload is to be distributed for optimal results. Should a minimum chunk size, greater than one, be set? The motivation for this is that due to the sequence having a fixed cost that needs amortizing, we will, for each minimum chunk size N, at least reduce the overhead to 1 / N, but if there are free nodes on the render farm perhaps they should be enlisted instead. The threshold is dependent on the ratio of the fixed cost to the marginal cost for an output frame, but it may not be possible to determine this a priori.
3.10.4. User Interface
It's just an API right now, with no clue as to how to turn this into something useful.